Results
9.1 Pilot coverage
The Phase 7 pilot ran via parallel API calls against the managed Anthropic-API substrate, with a deterministic seed regime and two per-model cost ledgers. The Haiku cascade consumed $12.73 across 1,277 CLI calls; the Sonnet judge consumed $0.48 across 23 rows; combined v0.4 spend was $13.21. Per-domain Haiku-cascade pairs are summarised below.
9.2 Per-domain primary contrasts (H1.v4–H4.v4)
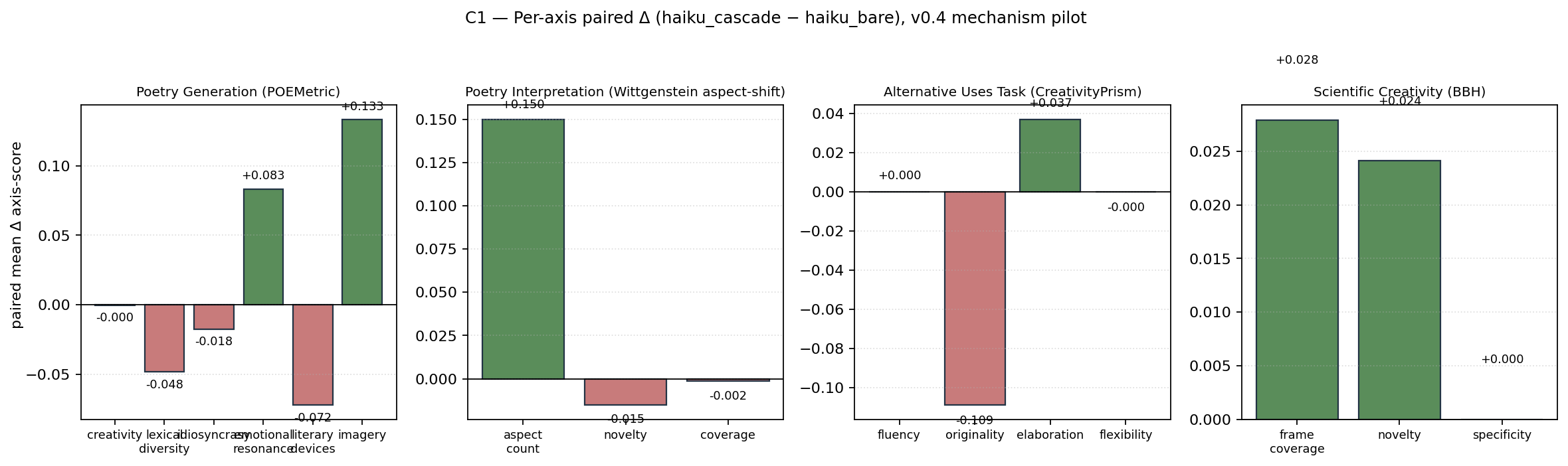
None of the four per-domain primary contrasts cross the supported threshold. Effect sizes range from g = -0.32 to g = 0.32. With per-domain n in the single digits, retrospective power is below 0.25 across the board; this is the underpowered-pilot reading rather than a strong null. The forest plot below shows per-domain g and the H5 fixed-effects pool.
9.3 Fixed-effects meta-pool (H5.v4)
Inverse-variance fixed-effects pool of cascade-vs-bare
ADR-005: fixed-effects chosen over random-effects given the small number of domain studies and homogeneity of the substrate. The reported interval is a Wald CI on the pooled g, not a BCa bootstrap.
9.4 Mechanism panel (H8a / H8b / H8c)
The mechanism panel is where v0.4's positive findings live. H8a tests the shadow revision pass directly: pair (score(revision), score(draft)) for every cascade item and ask whether the revision is reliably better. The answer is yes — g = 0.65, p = 1.2e-4, n = 27. This is the pratyabhijñā mechanism doing its job.
Shadow revision > draft (paired)
Paired score(revision) − score(draft) over all cascade items. The CI is a 10,000-resample BCa bootstrap on the paired mean Δ; the Hedges' g is reported alongside without a CI.
H8b asks the calibration question: given that the revision is usually better, can we predict which items will benefit? The v0.3 event-driven gate fires on internal vimarśa diagnostics and yields F1 = 0.52. The v0.4 learned gate (ADR-002) trains a small logistic head on the same diagnostics plus the proxy score gap and yields F1 = 0.65 — a real improvement.
Learned gate F1 > event-gated F1
Binary classifier metric; no bootstrap CI is reported. The H8b card intentionally omits CI / p-value because F1 contrasts are not Hedges' g and the v0.4 pilot did not bootstrap them.
learned_gate F1 = 0.647 vs event_gated F1 = 0.516. Binary classifier metric; no bootstrap CI is reported.
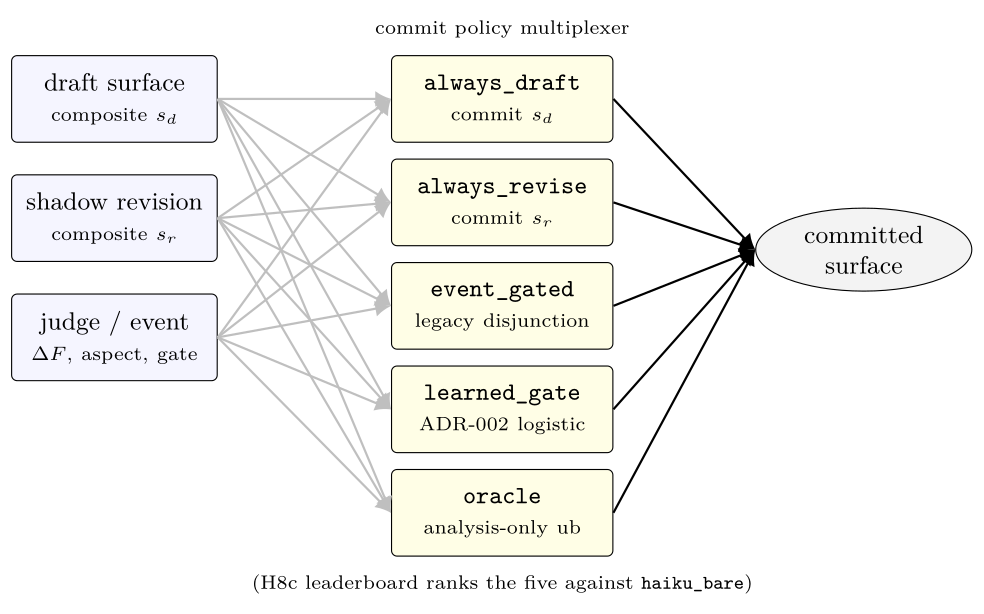
H8c places the policies on a single leaderboard against the bare control. always_revise leads, followed by learned_gate; event_gated sits with a CI that crosses zero; always_draft is at the floor. The pairwise gaps between the top two are not significant after Holm correction, which we read as: revision is the right default, and a smarter gate gets closer to the always-revise upper bound.
9.5 Judge-vs-proxy agreement (H9.v4)
H9 stress-tests the proxy composite scorer against a Sonnet-4.5 LLM-judge with a frozen prompt. Spearman ρ on the per-item delta is 0.00; sign-agreement is 56.5% over n = 23 items. We treat this as a methodological flag: the proxy scorer (length × fluency × lexical diversity) is not picking up what a calibrated LLM-judge rewards. The discussion page §10.4 unpacks the implications and the v0.5 metric-design ladder.