Hypotheses
v0.4 pre-registers four primary contrasts (H1–H4), a fixed-effects pool (H5), three mechanism decompositions (H8a/b/c), and one judge agreement check (H9). Two fairness controls (H6 with a 2× scorer budget on the bare arm, H7 with a generic two-pass revision baseline) are reported in the paper appendix. Click any card for the underlying definition; the results page renders these against the live stats.
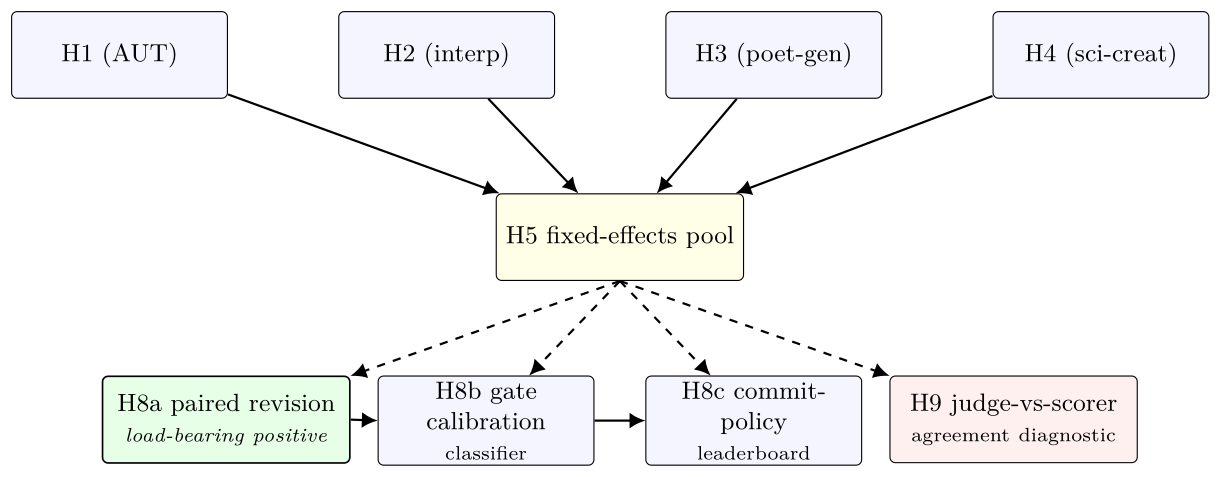
Primary cascade-vs-bare (H1–H4)
Cascade > bare on this domain
Cascade > bare on this domain
Cascade > bare on this domain
Cascade > bare on this domain
Pooled effect (H5)
Fixed-effects pool of cascade-vs-bare
ADR-005 inverse-variance fixed-effects meta-pool (fixed_effects_inverse_variance). The interval is a Wald CI on the pooled g, not a BCa bootstrap.
Mechanism decomposition (H8a/b/c)
Shadow revision > draft (paired)
Direct test of vimarśa: does the recursive revision pass produce a measurable surface lift? CI is on the paired mean Δ, not on the Hedges' g.
Learned gate F1 > event-gated F1
Binary classifier metric; no bootstrap CI is reported. The H8b card intentionally omits CI / p-value because F1 contrasts are not Hedges' g and the v0.4 pilot did not bootstrap them.
learned_gate F1 = 0.647 vs event_gated F1 = 0.516; binary-classifier metric, no bootstrap CI.
Commit-policy leaderboard — winner: always_revise
Pairwise paired permutations across always_draft / always_revise / event_gated / learned_gate; Holm-corrected.
Methodological flag (H9)
H9 reports Spearman ρ and sign-agreement between the proxy composite scorer and a calibrated Sonnet-4.5 LLM-judge over a held-out subset. Disagreement is treated as a flag against the proxy scorer's construct validity rather than as a refutation of the cascade. The discussion page §10.4 unpacks this.